- Home
- Microsoft
- 70-774 Exam
Microsoft 70-774 Free Practice Questions
Want to know 70-774 Exam Dumps features? Want to lear more about 70-774 Exam Questions and Answers experience? Study 70-774 Free Practice Questions. Gat a success with an absolute guarantee to pass Microsoft 70-774 (Perform Cloud Data Science with Azure Machine Learning (beta)) test on your first attempt.
Free 70-774 Demo Online For Microsoft Certifitcation:
NEW QUESTION 1
You need to integrate code and formatted text into an Azure Machine Learning experiment that enables interactive execution.
What should you use?
- A. a Jupyter notebook
- B. Azure Stream Analytics
- C. an Execute Python Script module
- D. an Execute R Script module
Answer: A
NEW QUESTION 2
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You plan to create a predictive analytics solution for credit risk assessment and fraud prediction in Azure Machine Learning. The Machine Learning workspace for the solution will be shared with other users in your organization. You will add assets to projects and conduct experiments in the workspace.
The experiments will be used for training models that will be published to provide scoring from web services. The experiment for fraud prediction will use Machine Learning modules and APIs to train the models and will predict probabilities in an Apache Hadoop ecosystem.
You finish training the model and are ready to publish a predictive web service that will provide the users with the ability to specify the data source and the save location of the results. The model includes a Split Data module.
Which two actions should you perform to convert the Machine Learning experiment to a predictive web service? To answer, drag the appropriate actions to the correct targets. Each action may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
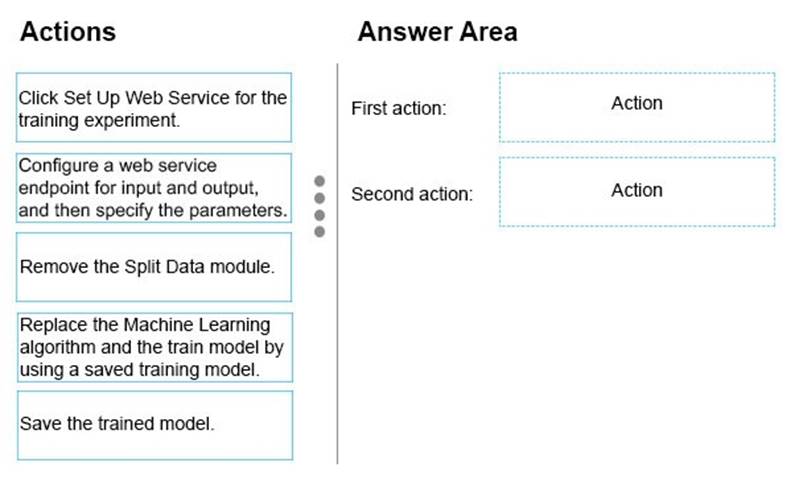
Answer:
Explanation: References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio/convert-training-experiment-to-scoring-experim
NEW QUESTION 3
You have an Azure Machine Learning experiment.
You discover that a model causes many errors in a production dataset. The model causes only few errors in the training data.
What is the cause of the errors?
- A. overfitting
- B. generalization
- C. underfitting
- D. a simple predictor
Answer: A
NEW QUESTION 4
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario
You plan to use Azure platform tools to detect and analyze food items in smart refrigerators. To provide families with an integrated experience for grocery shopping and cooking, the refrigerators will connect to other smart appliances, such as stoves and microwave ovens, on a LAN.
You plan to build an object recognition model by using the Microsoft Cognitive Toolkit. The object recognition model will receive input from the connected devices and send results to applications.
The training data will be derived from more than 10 TB of images. You will convert the raw images to the sparse format.
End of repeated scenario.
The image files to train the object recognition model are stored in a Microsoft SQL Server 2021 Standard edition database on an Azure virtual machine (VM).
You need to support R packages that can use full parallel threading and processing for RevoScaleR.
How should you implement R? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
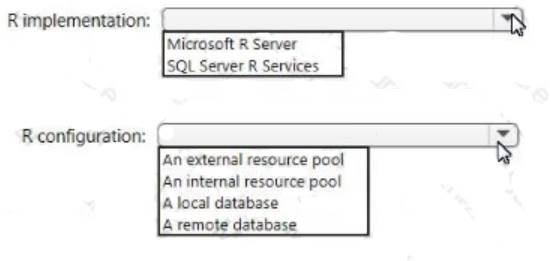
Answer:
Explanation: 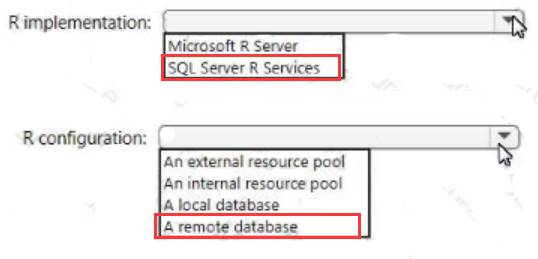
NEW QUESTION 5
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure ML experiment that contains an intermediate dataset. You need to explore data from the intermediate dataset by using Jupyter.
Solution: You add a web service input to retrieve the data for the data source, and then add the Execute R Script module.
Does this meet the goal?
Answer: B
NEW QUESTION 6
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario
You plan to use Azure platform tools to detect and analyze food items in smart refrigerators. To provide families with an integrated experience for grocery shopping and cooking, the refrigerators will connect to other smart appliances, such as stoves and microwave ovens, on a LAN.
You plan to build an object recognition model by using the Microsoft Cognitive Toolkit. The object recognition model will receive input from the connected devices and send results to applications.
The training data will be derived from more than 10 TB of images. You will convert the raw images to the sparse format.
End of repeated scenario.
You need to preprocess the training data by using a Principal Component Analysis (PCA) algorithm in the least amount of time possible. Which implementation method should you use?
- A. Azure HDInsight using HiveML
- B. Azure Machine Learning Studio and a custom Execute Python Script module
- C. Azure HDInsight using Microsoft R Server
- D. Azure Machine Learning Studio with a custom Execute R Script module
Answer: C
NEW QUESTION 7
You have data about the following:
• Users
• Movies
• User ratings of the movies
You need to predict whether a user will like a particular movie. Which Matchbox recommender should you use?
- A. Rating Prediction
- B. Related Users
- C. Item Recommendation
- D. Related Items
Answer: A
NEW QUESTION 8
You have an Azure Machine Learning environment. You are evaluating whether to use R code or Python.
Which three actions can you perform by using both R code and Python in the Machine Learning environment? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
- A. Preprocess, cleanse, and group data.
- B. Score a training model.
- C. Create visualizations.
- D. Create an untrained model that can be used with the Train Model module.
- E. Implement feature ranking.
Answer: ABC
NEW QUESTION 9
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You have a dataset that contains a column named Column1. Some of the values in Column1 are empty. You need to replace the empty values by using probabilistic Principal Component Analysis (PCA). The
solution must use a native module.
Which module should you use?
- A. Execute Python Script
- B. Clean Missing Data
- C. Select Columns in Dataset
- D. Import Data
- E. Normalize Data
- F. Edit Metadata
- G. Tune Model Hyperparameters
Answer: B
NEW QUESTION 10
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure ML experiment that contains an intermediate dataset. You need to explore data from the intermediate dataset by using Jupyter.
Solution: You add a Convert to ARFF module, and then add the Execute R Script module. Does this meet the goal?
Answer: B
NEW QUESTION 11
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are designing an Azure Machine Learning workflow.
You have a dataset that contains two million large digital photographs.
You plan to detect the presence of trees in the photographs. You need to ensure that your model supports the following:
Solution: You create an Azure notebook that supports the Microsoft Cognitive Toolkit. Does this meet the goal?
Answer: B
NEW QUESTION 12
You plan to use the Data Science Virtual Machine for development, but you are unfamiliar with R scripts. You need to generate R code for an experiment.
Which IDE should you use?
- A. XgBoost
- B. Rattle
- C. Vowpal Wabbit
- D. R Tools for Visual Studio
Answer: C
Explanation: References:
https://docs.microsoft.com/en-us/azure/machine-learning/data-science-virtual-machine/provision-vm
NEW QUESTION 13
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure ML experiment that contains an intermediate dataset. You need to explore data from the intermediate dataset by using Jupyter.
Solution: You add a Convert to CSV module to the Azure ML experiment and then open the module output in a new notebook.
Does this meet the goal?
Answer: A
NEW QUESTION 14
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario
You plan to use Azure platform tools to detect and analyze food items in smart refrigerators. To provide families with an integrated experience for grocery shopping and cooking, the refrigerators will connect to other smart appliances, such as stoves and microwave ovens, on a LAN.
You plan to build an object recognition model by using the Microsoft Cognitive Toolkit. The object recognition model will receive input from the connected devices and send results to applications.
The training data will be derived from more than 10 TB of images. You will convert the raw images to the sparse format.
End of repeated scenario.
You need to deploy a multiple-service solution that was developed already and published by other users in the Microsoft development community.
What should you use?
- A. the edX Data Science Learning Dashboard
- B. the Data Science Virtual Machine
- C. an Azure Machine Learning experiment
- D. Cortana Intelligence Gallery
Answer: C
NEW QUESTION 15
You deploy Microsoft Data Management Gateway.
You plan to use the Import Data module in Azure Machine Learning Studio to import data from an on-premises Microsoft SQL Server instance.
Which operation can you perform?
- A. Write the data back to the on-premises SQL Server instance.
- B. Filter the data as the data is being read by using the Import Data module.
- C. Run a Transact-SQL query and use SQL views to filter the data as the data is being read.
- D. Access the on-premises SQL Server instance without using credentials, and then import the data.
Answer: D
NEW QUESTION 16
You are building an Azure Machine Learning experiment.
You need to transform a string column that has 47 distinct values into a binary indicator column. The solution must use the One-vs-All Multiclass model.
Which module should you use?
- A. Select Column Transform
- B. Convert to Indicator Values
- C. Group Categorical Values
- D. Edit Metadata
Answer: B
Recommend!! Get the Full 70-774 dumps in VCE and PDF From 2passeasy, Welcome to Download: https://www.2passeasy.com/dumps/70-774/ (New 64 Q&As Version)

