- Home
- Microsoft
- 70-776 Exam
Microsoft 70-776 Free Practice Questions
70-776 Study Guides for Microsoft certification, Real Success Guaranteed with Updated 70-776 Exam Dumps. 100% PASS 70-776 Perform Big Data Engineering on Microsoft Cloud Services (beta) exam Today!
Free 70-776 Demo Online For Microsoft Certifitcation:
NEW QUESTION 1
You plan to add a file from Microsoft Azure Data Lake Store to Azure Data Catalog. You run the Data Catalog tool and select Data Lake Store as the data source.
Which information should you enter in the Store Account field to connect to the Data Lake Store?
- A. an email alias
- B. a server name
- C. a URL
- D. a subscription ID
Answer: C
NEW QUESTION 2
You have a Microsoft Azure SQL data warehouse that has 10 compute nodes.
You need to export 10 TB of data from a data warehouse table to several new flat files in Azure Blob storage. The solution must maximize the use of the available compute nodes.
What should you do?
- A. Use a transform activity in an Azure Data Factory pipeline.
- B. Execute the create table as select statement.
- C. Use the bcp utility.
- D. Execute the create external table as select statement.
Answer: C
NEW QUESTION 3
DRAG DROP
You need to design a Microsoft Azure solution to analyze text from a Twitter data stream. The solution must identify a sentiment score of positive, negative, or neutral for the tweets.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
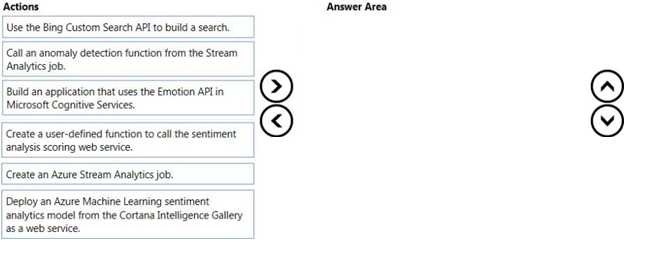
Answer:
Explanation: 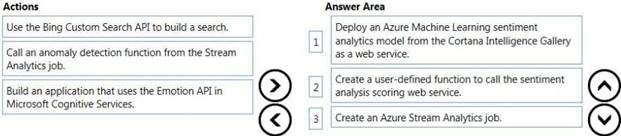
NEW QUESTION 4
You plan to use Microsoft Azure Event Hubs in Azure Stream Analytics to consume time-series
aggregations from several published data sources, such as IoT data, reference data, and social media. You expect several TB of data to be consumed daily. All the consumed data will be retained for one week.
You need to recommend a storage solution for the data. The solution must minimize costs. What should you recommend?
- A. Azure DocumentDB
- B. Azure Data Lake
- C. Azure Table Storage
- D. Azure Blob storage
Answer: B
NEW QUESTION 5
DRAG DROP
Note: This question is part of a series of questions that present the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario
You are migrating an existing on-premises data warehouse named LocalDW to Microsoft Azure. You will use an Azure SQL data warehouse named AzureDW for data storage and an Azure Data Factory named AzureDF for extract, transformation, and load (ETL) functions.
For each table in LocalDW, you create a table in AzureDW.
On the on-premises network, you have a Data Management Gateway.
Some source data is stored in Azure Blob storage. Some source data is stored on an on-premises Microsoft SQL Server instance. The instance has a table named Table1.
After data is processed by using AzureDF, the data must be archived and accessible forever. The archived data must meet a Service Level Agreement (SLA) for availability of 99 percent. If an Azure region fails, the archived data must be available for reading always. The storage solution for the archived data must minimize costs.
End of repeated scenario.
Which three actions should you perform in sequence to migrate the on-premises data warehouse to Azure SQL Data Warehouse? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
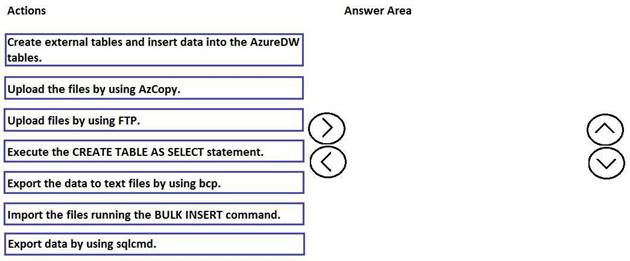
Answer:
Explanation:
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-load-from-sql-server-with-polybase
NEW QUESTION 6
You have a Microsoft Azure SQL data warehouse that contains information about community events. An Azure Data Factory job writes an updated CSV file in Azure Blob storage to Community/{date}/events.csv daily.
You plan to consume a Twitter feed by using Azure Stream Analytics and to correlate the feed to the community events.
You plan to use Stream Analytics to retrieve the latest community events data and to correlate the data to the Twitter feed data.
You need to ensure that when updates to the community events data is written to the CSV files, the Stream Analytics job can access the latest community events data.
What should you configure?
- A. an output that uses a blob storage sink and has a path pattern of Community/{date}
- B. an output that uses an event hub sink and the CSV event serialization format
- C. an input that uses a reference data source and has a path pattern of Community/{date}/events.csv
- D. an input that uses a reference data source and has a path pattern of Community/{date}
Answer: C
NEW QUESTION 7
You have a Microsoft Azure Data Lake Analytics service.
You need to provide a user with the ability to monitor Data Lake Analytics jobs. The solution must minimize the number of permissions assigned to the user.
Which role should you assign to the user?
- A. Reader
- B. Owner
- C. Contributor
- D. Data Lake Analytics Developer
Answer: A
Explanation:
References:
https://docs.microsoft.com/en-us/azure/data-lake-analytics/data-lake-analytics-manage-use-portal
NEW QUESTION 8
You have the following process:
• A CSV file is ingested by Microsoft Azure Stream Analytics.
• Scoring is performed by Azure Machine Learning.
• Stream Analytics returns sentiment scoring through a web service endpoint.
• Stream Analytics creates an output blob.
You need to view the output of the scoring operation and to evaluate the throughput to the Machine Learning models.
Which monitoring data should you evaluate from the Azure portal?
- A. the request count of Stream Analytics
- B. the request count of Machine Learning
- C. the event count of Stream Analytics
- D. the event count of Machine Learning
Answer: C
NEW QUESTION 9
Note: This question is part of a series of questions that present the same scenario. Each question in
the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are monitoring user queries to a Microsoft Azure SQL data warehouse that has six compute nodes.
You discover that compute node utilization is uneven. The rows_processed column from sys.dm_pdw_workers shows a significant variation in the number of rows being moved among the distributions for the same table for the same query.
You need to ensure that the load is distributed evenly across the compute nodes. Solution: You add a nonclustered columnstore index.
Does this meet the goal?
Answer: B
NEW QUESTION 10
DRAG DROP
You have a Microsoft Azure SQL data warehouse named DW1. Data is located to DW1 once daily at 01:00.
A user accidentally deletes data from a fact table in DW1 at 09:00.
You need to recover the lost data. The solution must prevent the need to change any connection strings and must minimize downtime.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
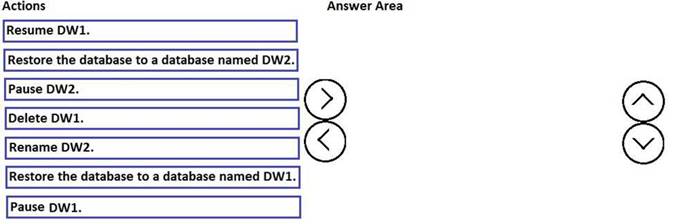
Answer:
Explanation: 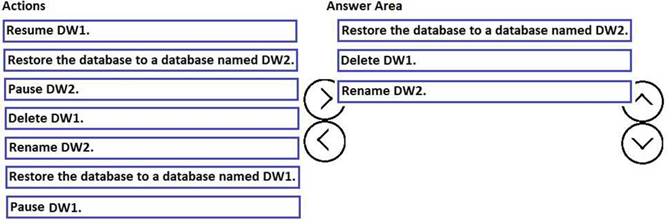
NEW QUESTION 11
You use Microsoft Azure Data Lake Store as the default storage for an Azure HDInsight cluster.
You establish an SSH connection to the HDInsight cluster.
You need to copy files from the HDInsight cluster to the Data LakeStore. Which command should you use?
- A. AzCopy
- B. hdfs dfs
- C. hadoop fs
- D. AdlCopy
Answer: D
NEW QUESTION 12
You have a Microsoft Azure Data Lake Store and an Azure Active Directory tenant.
You are developing an application that will access the Data Lake Store by using end-user credentials. You need to ensure that the application uses end-user authentication to access the Data Lake Store. What should you create?
- A. a Native Active Directory app registration
- B. a policy assignment that uses the Allowed resource types policy definition
- C. a Web app/API Active Directory app registration
- D. a policy assignment that uses the Allowed locations policy definition
Answer: A
Explanation:
References:
https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-end-user-authenticate-using-active-directory
NEW QUESTION 13
DRAG DROP
You have IoT devices that produce the following output.
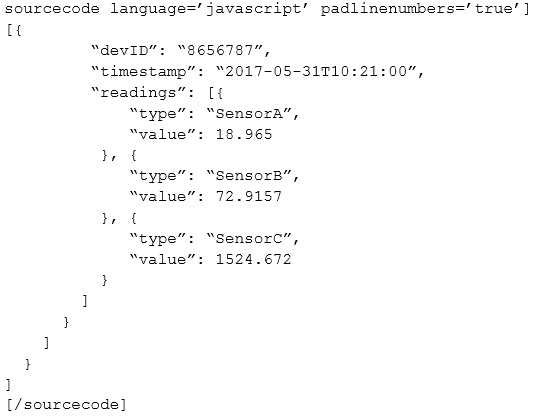
You need to use Microsoft Azure Stream Analytics to convert the output into the tabular format described in the following table.

How should you complete the Stream Analytics query? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
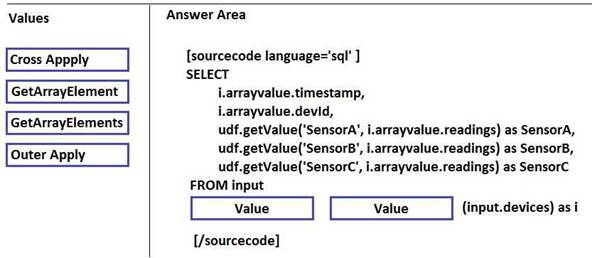
Answer:
Explanation: 
NEW QUESTION 14
HOTSPOT
Note: This question is part of a series of questions that present the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario
You are migrating an existing on-premises data warehouse named LocalDW to Microsoft Azure. You will use an Azure SQL data warehouse named AzureDW for data storage and an Azure Data Factory named AzureDF for extract, transformation, and load (ETL) functions.
For each table in LocalDW, you create a table in AzureDW.
On the on-premises network, you have a Data Management Gateway.
Some source data is stored in Azure Blob storage. Some source data is stored on an on-premises Microsoft SQL Server instance. The instance has a table named Table1.
After data is processed by using AzureDF, the data must be archived and accessible forever. The archived data must meet a Service Level Agreement (SLA) for availability of 99 percent. If an Azure region fails, the archived data must be available for reading always. The storage solution for the archived data must minimize costs.
End of repeated scenario.
How should you configure the storage to archive the source data? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

Answer:
Explanation:
References:
https://docs.microsoft.com/en-us/azure/storage/blobs/storage-blob-storage-tiers
NEW QUESTION 15
You have an on-premises deployment of Active Directory named contoso.com. You plan to deploy a Microsoft Azure SQL data warehouse.
You need to ensure that the data warehouse can be accessed by contoso.com users.
Which two components should you deploy? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A. Azure AD Privileged Identity Management
- B. Azure Information Protection
- C. Azure Active Directory
- D. Azure AD Connect
- E. Cloud App Discovery
- F. Azure Active Directory B2C
Answer: CD
NEW QUESTION 16
You have a file in a Microsoft Azure Data Lake Store that contains sales data. The file contains sales amounts by salesperson, by city, and by state.
You need to use U-SQL to calculate the percentage of sales that each city has for its respective state. Which code should you use?


- A. Option A
- B. Option B
- C. Option C
- D. Option D
Answer: A
NEW QUESTION 17
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this sections, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are monitoring user queries to a Microsoft Azure SQL data warehouse that has six compute nodes.
You discover that compute node utilization is uneven. The rows_processed column from sys.dm_pdw_workers shows a significant variation in the number of rows being moved among the distributions for the same table for the same query.
You need to ensure that the load is distributed evenly across the compute nodes. Solution: You change the table to use a column that is not skewed for hash distribution. Does this meet the goal?
Answer: A
NEW QUESTION 18
HOTSPOT
You have a Microsoft Azure Data Lake Analytics service.
You have a file named Employee.tsv that contains data on employees. Employee.tsv contains seven columns named EmpId, Start, FirstName, LastName, Age, Department, and Title.
You need to create a Data Lake Analytics jobs to transform Employee.tsv, define a schema for the data, and output the data to a CSV file. The outputted data must contain only employees who are in the sales department. The Age column must allow NULL.
How should you complete the U-SQL code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
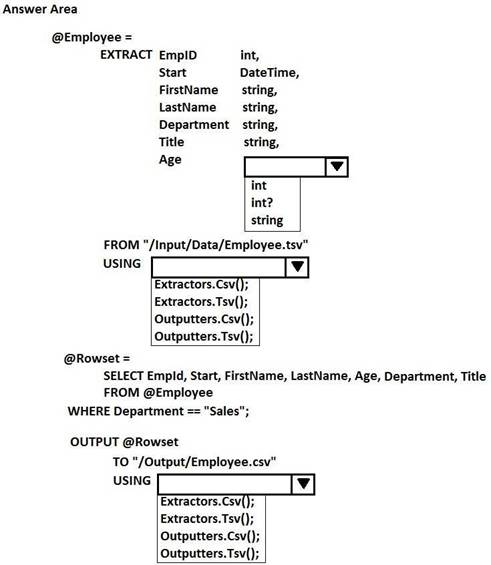
Answer:
Explanation:
References:
https://docs.microsoft.com/en-us/azure/data-lake-analytics/data-lake-analytics-u-sql-get-started
P.S. Easily pass 70-776 Exam with 91 Q&As Certleader Dumps & pdf Version, Welcome to Download the Newest Certleader 70-776 Dumps: https://www.certleader.com/70-776-dumps.html (91 New Questions)

