- Home
- Cloudera
- CCA-500 Exam
Cloudera CCA-500 Free Practice Questions
It is impossible to pass Cloudera CCA-500 exam without any help in the short term. Come to us soon and find the most advanced, correct and guaranteed . You will get a surprising result by our .
Online CCA-500 free questions and answers of New Version:
NEW QUESTION 1
You need to analyze 60,000,000 images stored in JPEG format, each of which is approximately 25 KB. Because you Hadoop cluster isn’t optimized for storing and processing many small files, you decide to do the following actions:
1. Group the individual images into a set of larger files
2. Use the set of larger files as input for a MapReduce job that processes them directly with python using Hadoop streaming.
Which data serialization system gives the flexibility to do this?
- A. CSV
- B. XML
- C. HTML
- D. Avro
- E. SequenceFiles
- F. JSON
Answer: E
Explanation: Sequence files are block-compressed and provide direct serialization and deserialization of several arbitrary data types (not just text). Sequence files can be generated as the output of other MapReduce tasks and are an efficient intermediate representation for data that is passing from one MapReduce job to anther.
NEW QUESTION 2
You want to node to only swap Hadoop daemon data from RAM to disk when absolutely necessary. What should you do?
- A. Delete the /dev/vmswap file on the node
- B. Delete the /etc/swap file on the node
- C. Set the ram.swap parameter to 0 in core-site.xml
- D. Set vm.swapfile file on the node
- E. Delete the /swapfile file on the node
Answer: D
NEW QUESTION 3
You are configuring a server running HDFS, MapReduce version 2 (MRv2) on YARN running Linux. How must you format underlying file system of each DataNode?
- A. They must be formatted as HDFS
- B. They must be formatted as either ext3 or ext4
- C. They may be formatted in any Linux file system
- D. They must not be formatted - - HDFS will format the file system automatically
Answer: B
NEW QUESTION 4
On a cluster running MapReduce v2 (MRv2) on YARN, a MapReduce job is given a directory of 10 plain text files as its input directory. Each file is made up of 3 HDFS blocks. How many Mappers will run?
- A. We cannot say; the number of Mappers is determined by the ResourceManager
- B. We cannot say; the number of Mappers is determined by the developer
- C. 30
- D. 3
- E. 10
- F. We cannot say; the number of mappers is determined by the ApplicationMaster
Answer: E
NEW QUESTION 5
Your Hadoop cluster contains nodes in three racks. You have not configured the dfs.hosts property in the NameNode’s configuration file. What results?
- A. The NameNode will update the dfs.hosts property to include machines running the DataNode daemon on the next NameNode reboot or with the command dfsadmin–refreshNodes
- B. No new nodes can be added to the cluster until you specify them in the dfs.hosts file
- C. Any machine running the DataNode daemon can immediately join the cluster
- D. Presented with a blank dfs.hosts property, the NameNode will permit DataNodes specified in mapred.hosts to join the cluster
Answer: C
NEW QUESTION 6
You want to understand more about how users browse your public website. For example, you want to know which pages they visit prior to placing an order. You have a server farm of 200 web servers hosting your website. Which is the most efficient process to gather these web server across logs into your Hadoop cluster analysis?
- A. Sample the web server logs web servers and copy them into HDFS using curl
- B. Ingest the server web logs into HDFS using Flume
- C. Channel these clickstreams into Hadoop using Hadoop Streaming
- D. Import all user clicks from your OLTP databases into Hadoop using Sqoop
- E. Write a MapReeeduce job with the web servers for mappers and the Hadoop cluster nodes for reducers
Answer: B
Explanation: Apache Flume is a service for streaming logs into Hadoop.
Apache Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of streaming data into the Hadoop Distributed File System (HDFS). It has a simple and flexible architecture based on streaming data flows; and is robust and fault tolerant with tunable reliability mechanisms for failover and recovery.
NEW QUESTION 7
Cluster Summary:
45 files and directories, 12 blocks = 57 total. Heap size is 15.31 MB/193.38MB(7%)
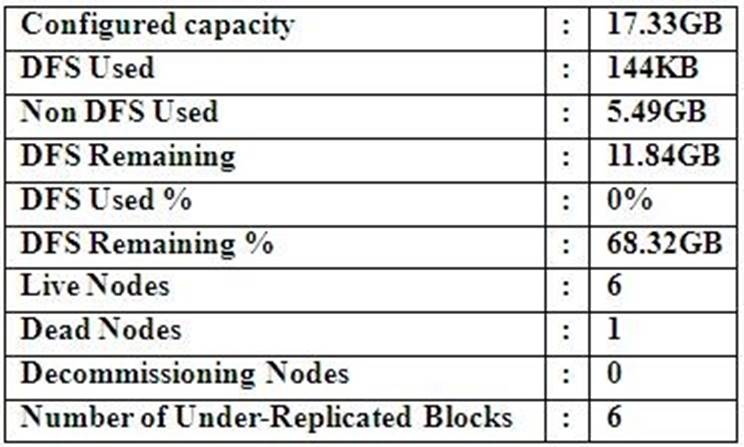
Refer to the above screenshot.
You configure a Hadoop cluster with seven DataNodes and on of your monitoring UIs displays the details shown in the exhibit.
What does the this tell you?
- A. The DataNode JVM on one host is not active
- B. Because your under-replicated blocks count matches the Live Nodes, one node is dead, and your DFS Used % equals 0%, you can’t be certain that your cluster has all the data you’ve written it.
- C. Your cluster has lost all HDFS data which had bocks stored on the dead DatNode
- D. The HDFS cluster is in safe mode
Answer: A
NEW QUESTION 8
Identify two features/issues that YARN is designated to address:(Choose two)
- A. Standardize on a single MapReduce API
- B. Single point of failure in the NameNode
- C. Reduce complexity of the MapReduce APIs
- D. Resource pressure on the JobTracker
- E. Ability to run framework other than MapReduce, such as MPI
- F. HDFS latency
Answer: DE
Explanation: Reference:http://www.revelytix.com/?q=content/hadoop-ecosystem(YARN, first para)
NEW QUESTION 9
You have A 20 node Hadoop cluster, with 18 slave nodes and 2 master nodes running HDFS High Availability (HA). You want to minimize the chance of data loss in your cluster. What should you do?
- A. Add another master node to increase the number of nodes running the JournalNode which increases the number of machines available to HA to create a quorum
- B. Set an HDFS replication factor that provides data redundancy, protecting against node failure
- C. Run a Secondary NameNode on a different master from the NameNode in order to provide automatic recovery from a NameNode failure.
- D. Run the ResourceManager on a different master from the NameNode in order to load- share HDFS metadata processing
- E. Configure the cluster’s disk drives with an appropriate fault tolerant RAID level
Answer: D
NEW QUESTION 10
You have just run a MapReduce job to filter user messages to only those of a selected geographical region. The output for this job is in a directory named westUsers, located just below your home directory in HDFS. Which command gathers these into a single file on your local file system?
- A. Hadoop fs –getmerge –R westUsers.txt
- B. Hadoop fs –getemerge westUsers westUsers.txt
- C. Hadoop fs –cp westUsers/* westUsers.txt
- D. Hadoop fs –get westUsers westUsers.txt
Answer: B
NEW QUESTION 11
You are running a Hadoop cluster with MapReduce version 2 (MRv2) on YARN. You consistently see that MapReduce map tasks on your cluster are running slowly because of excessive garbage collection of JVM, how do you increase JVM heap size property to 3GB to optimize performance?
- A. yarn.application.child.java.opts=-Xsx3072m
- B. yarn.application.child.java.opts=-Xmx3072m
- C. mapreduce.map.java.opts=-Xms3072m
- D. mapreduce.map.java.opts=-Xmx3072m
Answer: C
Explanation: Reference:http://hortonworks.com/blog/how-to-plan-and-configure-yarn-in-hdp-2-0/
NEW QUESTION 12
Table schemas in Hive are:
- A. Stored as metadata on the NameNode
- B. Stored along with the data in HDFS
- C. Stored in the Metadata
- D. Stored in ZooKeeper
Answer: B
NEW QUESTION 13
What does CDH packaging do on install to facilitate Kerberos security setup?
- A. Automatically configures permissions for log files at & MAPRED_LOG_DIR/userlogs
- B. Creates users for hdfs and mapreduce to facilitate role assignment
- C. Creates directories for temp, hdfs, and mapreduce with the correct permissions
- D. Creates a set of pre-configured Kerberos keytab files and their permissions
- E. Creates and configures your kdc with default cluster values
Answer: B
NEW QUESTION 14
You are running Hadoop cluster with all monitoring facilities properly configured. Which scenario will go undeselected?
- A. HDFS is almost full
- B. The NameNode goes down
- C. A DataNode is disconnected from the cluster
- D. Map or reduce tasks that are stuck in an infinite loop
- E. MapReduce jobs are causing excessive memory swaps
Answer: B
NEW QUESTION 15
You are working on a project where you need to chain together MapReduce, Pig jobs. You also need the ability to use forks, decision points, and path joins. Which ecosystem project should you use to perform these actions?
- A. Oozie
- B. ZooKeeper
- C. HBase
- D. Sqoop
- E. HUE
Answer: A
NEW QUESTION 16
In CDH4 and later, which file contains a serialized form of all the directory and files inodes in the filesystem, giving the NameNode a persistent checkpoint of the filesystem metadata?
- A. fstime
- B. VERSION
- C. Fsimage_N (where N reflects transactions up to transaction ID N)
- D. Edits_N-M (where N-M transactions between transaction ID N and transaction ID N)
Answer: C
Explanation: Reference:http://mikepluta.com/tag/namenode/
P.S. Certleader now are offering 100% pass ensure CCA-500 dumps! All CCA-500 exam questions have been updated with correct answers: https://www.certleader.com/CCA-500-dumps.html (60 New Questions)

