- Home
- Microsoft
- DP-201 Exam
Microsoft DP-201 Free Practice Questions
It is impossible to pass Microsoft DP-201 exam without any help in the short term. Come to Pass4sure soon and find the most advanced, correct and guaranteed Microsoft DP-201 practice questions. You will get a surprising result by our Improve Designing an Azure Data Solution practice guides.
Also have DP-201 free dumps questions for you:
NEW QUESTION 1
You are designing a Spark job that performs batch processing of daily web log traffic.
When you deploy the job in the production environment, it must meet the following requirements:
 Run once a day.
Run once a day.
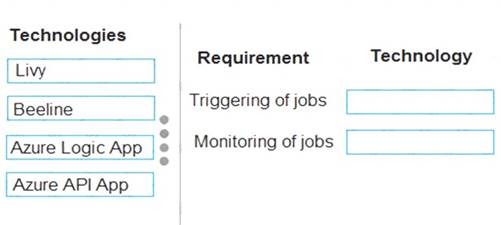
Display status information on the company intranet as the job runs. You need to recommend technologies for triggering and monitoring jobs.
Which technologies should you recommend? To answer, drag the appropriate technologies to the correct locations. Each technology may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: Livy
You can use Livy to run interactive Spark shells or submit batch jobs to be run on Spark. Box 2: Beeline
Apache Beeline can be used to run Apache Hive queries on HDInsight. You can use Beeline with Apache Spark.
Note: Beeline is a Hive client that is included on the head nodes of your HDInsight cluster. Beeline uses JDBC to connect to HiveServer2, a service hosted on your HDInsight cluster. You can also use Beeline to access Hive on HDInsight remotely over the internet.
References:
https://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-livy-rest-interface https://docs.microsoft.com/en-us/azure/hdinsight/hadoop/apache-hadoop-use-hive-beeline
NEW QUESTION 2
You are designing a data processing solution that will implement the lambda architecture pattern. The solution will use Spark running on HDInsight for data processing.
You need to recommend a data storage technology for the solution.
Which two technologies should you recommend? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
- A. Azure Cosmos DB
- B. Azure Service Bus
- C. Azure Storage Queue
- D. Apache Cassandra
- E. Kafka HDInsight
Answer: AE
Explanation:
To implement a lambda architecture on Azure, you can combine the following technologies to accelerate realtime big data analytics:
Azure Cosmos DB, the industry's first globally distributed, multi-model database service.
Apache Spark for Azure HDInsight, a processing framework that runs large-scale data analytics applications
Azure Cosmos DB change feed, which streams new data to the batch layer for HDInsight to process The Spark to Azure Cosmos DB Connector
E: You can use Apache Spark to stream data into or out of Apache Kafka on HDInsight using DStreams. References:
https://docs.microsoft.com/en-us/azure/cosmos-db/lambda-architecture
NEW QUESTION 3
You have a Windows-based solution that analyzes scientific data. You are designing a cloud-based solution that performs real-time analysis of the data.
You need to design the logical flow for the solution.
Which two actions should you recommend? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Send data from the application to an Azure Stream Analytics job.
- B. Use an Azure Stream Analytics job on an edge devic
- C. Ingress data from an Azure Data Factory instance and build queries that output to Power BI.
- D. Use an Azure Stream Analytics job in the clou
- E. Ingress data from the Azure Event Hub instance and build queries that output to Power BI.
- F. Use an Azure Stream Analytics job in the clou
- G. Ingress data from an Azure Event Hub instance and build queries that output to Azure Data Lake Storage.
- H. Send data from the application to Azure Data Lake Storage.
- I. Send data from the application to an Azure Event Hub instance.
Answer: CF
Explanation:
Stream Analytics has first-class integration with Azure data streams as inputs from three kinds of resources: Azure Event Hubs
Azure IoT Hub Azure Blob storage References:
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-define-inputs
NEW QUESTION 4
HOTSPOT
You need to ensure that security policies for the unauthorized detection system are met. What should you recommend? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.

- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: Blob storage
Configure blob storage for audit logs.
Scenario: Unauthorized usage of the Planning Assistance data must be detected as quickly as possible. Unauthorized usage is determined by looking for an unusual pattern of usage.
Data used for Planning Assistance must be stored in a sharded Azure SQL Database. Box 2: Web Apps
SQL Advanced Threat Protection (ATP) is to be used.
One of Azure’s most popular service is App Service which enables customers to build and host web applications in the programming language of their choice without managing infrastructure. App Service offers auto-scaling and high availability, supports both Windows and Linux. It also supports automated deployments from GitHub, Visual Studio Team Services or any Git repository. At RSA, we announced that Azure Security Center leverages the scale of the cloud to identify attacks targeting App Service applications.
References:
https://azure.microsoft.com/sv-se/blog/azure-security-center-can-identify-attacks-targeting-azure-app-service-ap
NEW QUESTION 5
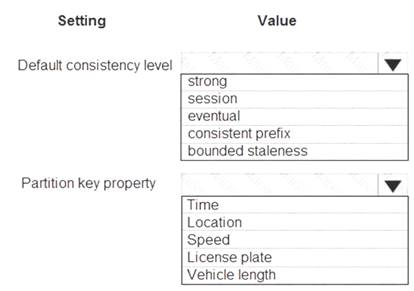
You need to design the SensorData collection.
What should you recommend? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: Eventual
Traffic data insertion rate must be maximized.
Sensor data must be stored in a Cosmos DB named treydata in a collection named SensorData
With Azure Cosmos DB, developers can choose from five well-defined consistency models on the consistency spectrum. From strongest to more relaxed, the models include strong, bounded staleness, session, consistent prefix, and eventual consistency.
Box 2: License plate
This solution reports on all data related to a specific vehicle license plate. The report must use data from the SensorData collection.
References:
https://docs.microsoft.com/en-us/azure/cosmos-db/consistency-levels
NEW QUESTION 6
You are designing a recovery strategy for your Azure SQL Databases.
The recovery strategy must use default automated backup settings. The solution must include a Point-in time restore recovery strategy.
You need to recommend which backups to use and the order in which to restore backups.
What should you recommend? To answer, select the appropriate configuration in the answer area.
NOTE: Each correct selection is worth one point.

- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
All Basic, Standard, and Premium databases are protected by automatic backups. Full backups are taken every week, differential backups every day, and log backups every 5 minutes.
References:
https://azure.microsoft.com/sv-se/blog/azure-sql-database-point-in-time-restore/
NEW QUESTION 7
You need to optimize storage for CONT_SQL3. What should you recommend?
- A. AlwaysOn
- B. Transactional processing
- C. General
- D. Data warehousing
Answer: B
Explanation:
CONT_SQL3 with the SQL Server role, 100 GB database size, Hyper-VM to be migrated to Azure VM. The storage should be configured to optimized storage for database OLTP workloads.
Azure SQL Database provides three basic in-memory based capabilities (built into the underlying database engine) that can contribute in a meaningful way to performance improvements:
In-Memory Online Transactional Processing (OLTP)
Clustered columnstore indexes intended primarily for Online Analytical Processing (OLAP) workloads Nonclustered columnstore indexes geared towards Hybrid Transactional/Analytical Processing (HTAP) workloads
References:
https://www.databasejournal.com/features/mssql/overview-of-in-memory-technologies-of-azure-sqldatabase.htm
NEW QUESTION 8
You plan to migrate data to Azure SQL Database.
The database must remain synchronized with updates to Microsoft Azure and SQL Server. You need to set up the database as a subscriber.
What should you recommend?
- A. Azure Data Factory
- B. SQL Server Data Tools
- C. Data Migration Assistant
- D. SQL Server Agent for SQL Server 2021 or later
- E. SQL Server Management Studio 17.9.1 or later
Answer: E
Explanation:
To set up the database as a subscriber we need to configure database replication. You can use SQL Server Management Studio to configure replication. Use the latest versions of SQL Server Management Studio in order to be able to use all the features of Azure SQL Database.
References:
https://www.sqlshack.com/sql-server-database-migration-to-azure-sql-database-using-sql-server-transactionalrep
NEW QUESTION 10
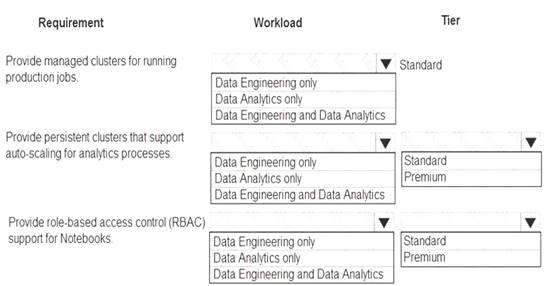
You are designing a solution for a company. You plan to use Azure Databricks. You need to recommend workloads and tiers to meet the following requirements:
 Provide managed clusters for running production jobs.
Provide managed clusters for running production jobs.
Provide persistent clusters that support auto-scaling for analytics processes.
Provide role-based access control (RBAC) support for Notebooks.
What should you recommend? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: Data Engineering Only
Box 2: Data Engineering and Data Analytics Box 3: Standard
Box 4: Data Analytics only Box 5: Premium
Premium required for RBAC. Data Analytics Premium Tier provide interactive workloads to analyze data collaboratively with notebooks
References:
https://azure.microsoft.com/en-us/pricing/details/databricks/
NEW QUESTION 11
You need to design the unauthorized data usage detection system. What Azure service should you include in the design?
- A. Azure Databricks
- B. Azure SQL Data Warehouse
- C. Azure Analysis Services
- D. Azure Data Factory
Answer: B
NEW QUESTION 12
A company is designing a solution that uses Azure Databricks.
The solution must be resilient to regional Azure datacenter outages. You need to recommend the redundancy type for the solution. What should you recommend?
- A. Read-access geo-redundant storage
- B. Locally-redundant storage
- C. Geo-redundant storage
- D. Zone-redundant storage
Answer: C
Explanation:
If your storage account has GRS enabled, then your data is durable even in the case of a complete regional outage or a disaster in which the primary region isn’t recoverable.
References:
https://medium.com/microsoftazure/data-durability-fault-tolerance-resilience-in-azure-databricks- 95392982bac7
NEW QUESTION 13
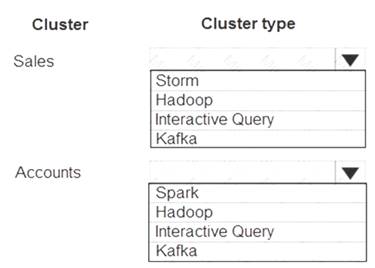
A company stores large datasets in Azure, including sales transactions and customer account information. You must design a solution to analyze the data. You plan to create the following HDInsight clusters:
You need to ensure that the clusters support the query requirements.
Which cluster types should you recommend? To answer, select the appropriate configuration in the answer area.
NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: Interactive Query
Choose Interactive Query cluster type to optimize for ad hoc, interactive queries. Box 2: Hadoop
Choose Apache Hadoop cluster type to optimize for Hive queries used as a batch process.
Note: In Azure HDInsight, there are several cluster types and technologies that can run Apache Hive queries. When you create your HDInsight cluster, choose the appropriate cluster type to help optimize performance for your workload needs.
For example, choose Interactive Query cluster type to optimize for ad hoc, interactive queries. Choose Apache Hadoop cluster type to optimize for Hive queries used as a batch process. Spark and HBase cluster types can also run Hive queries.
References:
https://docs.microsoft.com/bs-latn-ba/azure/hdinsight/hdinsight-hadoop-optimize-hive-query?toc=%2Fko-kr%2
NEW QUESTION 14
You need to recommend the appropriate storage and processing solution? What should you recommend?
- A. Enable auto-shrink on the database.
- B. Flush the blob cache using Windows PowerShell.
- C. Enable Apache Spark RDD (RDD) caching.
- D. Enable Databricks IO (DBIO) caching.
- E. Configure the reading speed using Azure Data Studio.
Answer: C
Explanation:
Scenario: You must be able to use a file system view of data stored in a blob. You must build an architecture that will allow Contoso to use the DB FS filesystem layer over a blob store.
Databricks File System (DBFS) is a distributed file system installed on Azure Databricks clusters. Files in DBFS persist to Azure Blob storage, so you won’t lose data even after you terminate a cluster.
The Databricks Delta cache, previously named Databricks IO (DBIO) caching, accelerates data reads by creating copies of remote files in nodes’ local storage using a fast intermediate data format. The data is cached automatically whenever a file has to be fetched from a remote location. Successive reads of the same data are then performed locally, which results in significantly improved reading speed.
NEW QUESTION 15
You are designing an Azure SQL Data Warehouse. You plan to load millions of rows of data into the data warehouse each day.
You must ensure that staging tables are optimized for data loading. You need to design the staging tables.
What type of tables should you recommend?
- A. Round-robin distributed table
- B. Hash-distributed table
- C. Replicated table
- D. External table
Answer: A
Explanation:
To achieve the fastest loading speed for moving data into a data warehouse table, load data into a staging table. Define the staging table as a heap and use round-robin for the distribution option.
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/guidance-for-loading-data
NEW QUESTION 16
A company has an application that uses Azure SQL Database as the data store.
The application experiences a large increase in activity during the last month of each year.
You need to manually scale the Azure SQL Database instance to account for the increase in data write operations.
Which scaling method should you recommend?
- A. Scale up by using elastic pools to distribute resources.
- B. Scale out by sharding the data across databases.
- C. Scale up by increasing the database throughput units.
Answer: C
Explanation:
As of now, the cost of running an Azure SQL database instance is based on the number of Database Throughput Units (DTUs) allocated for the database. When determining the number of units to allocate for the
solution, a major contributing factor is to identify what processing power is needed to handle the volume of expected requests.
Running the statement to upgrade/downgrade your database takes a matter of seconds.
NEW QUESTION 17
You are evaluating data storage solutions to support a new application.
You need to recommend a data storage solution that represents data by using nodes and relationships in graph structures.
Which data storage solution should you recommend?
- A. Blob Storage
- B. Cosmos DB
- C. Data Lake Store
- D. HDInsight
Answer: B
Explanation:
For large graphs with lots of entities and relationships, you can perform very complex analyses very quickly. Many graph databases provide a query language that you can use to traverse a network of relationships efficiently.
Relevant Azure service: Cosmos DB
References:
https://docs.microsoft.com/en-us/azure/architecture/guide/technology-choices/data-store-overview
NEW QUESTION 19
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these
questions will not appear in the review screen.
You are designing an HDInsight/Hadoop cluster solution that uses Azure Data Lake Gen1 Storage. The solution requires POSIX permissions and enables diagnostics logging for auditing.
You need to recommend solutions that optimize storage.
Proposed Solution: Ensure that files stored are larger than 250MB. Does the solution meet the goal?
Answer: A
Explanation:
Depending on what services and workloads are using the data, a good size to consider for files is 256 MB or greater. If the file sizes cannot be batched when landing in Data Lake Storage Gen1, you can have a separate compaction job that combines these files into larger ones.
Note: POSIX permissions and auditing in Data Lake Storage Gen1 comes with an overhead that becomes apparent when working with numerous small files. As a best practice, you must batch your data into larger files versus writing thousands or millions of small files to Data Lake Storage Gen1. Avoiding small file sizes can have multiple benefits, such as:
Lowering the authentication checks across multiple files Reduced open file connections
Faster copying/replication
Fewer files to process when updating Data Lake Storage Gen1 POSIX permissions References:
https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-best-practices
NEW QUESTION 20
A company stores sensitive information about customers and employees in Azure SQL Database. You need to ensure that the sensitive data remains encrypted in transit and at rest.
What should you recommend?
- A. Transparent Data Encryption
- B. Always Encrypted with secure enclaves
- C. Azure Disk Encryption
- D. SQL Server AlwaysOn
Answer: B
Explanation:
References:
https://cloudblogs.microsoft.com/sqlserver/2021/12/17/confidential-computing-using-always-encrypted-withsec
NEW QUESTION 21
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are designing an Azure SQL Database that will use elastic pools. You plan to store data about customers in a table. Each record uses a value for CustomerID.
You need to recommend a strategy to partition data based on values in CustomerID. Proposed Solution: Separate data into customer regions by using horizontal partitioning. Does the solution meet the goal?
Answer: B
Explanation:
We should use Horizontal Partitioning through Sharding, not divide through regions.
Note: Horizontal Partitioning - Sharding: Data is partitioned horizontally to distribute rows across a scaled out data tier. With this approach, the schema is identical on all participating databases. This approach is also called “sharding”. Sharding can be performed and managed using (1) the elastic database tools libraries or (2)
self-sharding. An elastic query is used to query or compile reports across many shards.
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-elastic-query-overview
NEW QUESTION 22
You plan to use an Azure SQL data warehouse to store the customer data. You need to recommend a disaster recovery solution for the data warehouse. What should you include in the recommendation?
- A. AzCopy
- B. Read-only replicas
- C. AdICopy
- D. Geo-Redundant backups
Answer: D
Explanation:
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/backup-and-restore
NEW QUESTION 23
You plan to deploy an Azure SQL Database instance to support an application. You plan to use the DTUbased purchasing model.
Backups of the database must be available for 30 days and point-in-time restoration must be possible. You need to recommend a backup and recovery policy.
What are two possible ways to achieve the goal? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
- A. Use the Premium tier and the default backup retention policy.
- B. Use the Basic tier and the default backup retention policy.
- C. Use the Standard tier and the default backup retention policy.
- D. Use the Standard tier and configure a long-term backup retention policy.
- E. Use the Premium tier and configure a long-term backup retention policy.
Answer: DE
Explanation:
The default retention period for a database created using the DTU-based purchasing model depends on the service tier:
Basic service tier is 1 week.
Standard service tier is 5 weeks.
Premium service tier is 5 weeks.
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-long-term-retention
NEW QUESTION 24
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
A company is developing a solution to manage inventory data for a group of automotive repair shops. The solution will use Azure SQL Data Warehouse as the data store.
Shops will upload data every 10 days.
Data corruption checks must run each time data is uploaded. If corruption is detected, the corrupted data must be removed.
You need to ensure that upload processes and data corruption checks do not impact reporting and analytics processes that use the data warehouse.
Proposed solution: Configure database-level auditing in Azure SQL Data Warehouse and set retention to 10 days.
Does the solution meet the goal?
Answer: B
Explanation:
Instead, create a user-defined restore point before data is uploaded. Delete the restore point after data corruption checks complete.
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/backup-and-restore
Thanks for reading the newest DP-201 exam dumps! We recommend you to try the PREMIUM DumpSolutions DP-201 dumps in VCE and PDF here: https://www.dumpsolutions.com/DP-201-dumps/ (74 Q&As Dumps)